by Pierre Nugues
Second edition: August 2014
Pages: 662
Published by Springer
Errata to the Second Edition
A list of errata to the first edition is available here.
Chapter 5
Page 137, Unix script. Replace the enumerated list with:
tr -cs ’A-Za-z’ ’\n’ <input_file > token_file
Tokenize the input and create a file with the unigrams.tail +2 < token_file > next_token_file
Create a second unigram file starting at the second word of the first tokenized file (+2).paste token_file next_token_file > bigrams
Merge the lines (the tokens) pairwise. Each line contains the words at index i and i + 1 separated with a tabulation.- And we count the bigrams as in the previous script.
Page 161, in the Perl program, replace the two occurrences of:
log($p) +
with
log($p) -
Chapter 6
Page 193, Figure 6.9. Replace the figure with
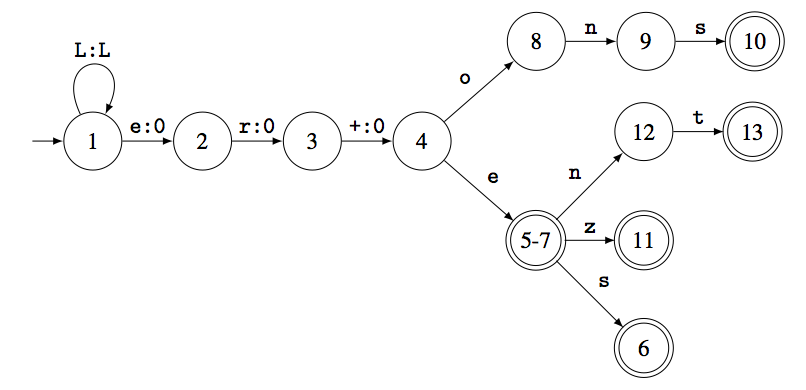
Corrected figure [tikz].
Chapter 11
Page 325, Figure 11.2. Replace the rightmost NP2 with NP1. Corrected figure [tikz].
Chapter 13
Table 13.12, page 435. The analysis is for the sentence The waiter brought the meal and not The waiter brought a meal
Table 13.12, page 435. Sitxth row from bottom. Change (VBD, NN) to (VBD, DT)
Chapter 15
Page 506, Figure 15.13. Replace the two node labels below the noun root node with respectively concrete and abstract. Corrected figure [tikz].
Chapter 16
Page 530, Table 16.8, 4th row. Move the word major from the 3rd column to the 4th column.
Institutionen för Datavetenskap 2014. Ansvarig: Pierre Nugues
Last update: Saturday, 19-Dec-2015 16:37:13 CET